Heroku Dynos: Standard vs Performance
We benchmark the actual difference in latency between Heroku's Standard-1x, Standard-2x, Performance-M and Performance-L dynos.
December 24, 2020 | heroku dynos performance | by: Colin Dellow
Heroku is a phenomenal platform. It enables nimbleness by offloading much of your application's operations headache onto Heroku's dedicated infrastructure team.
That nimbleness comes with a tradeoff. Instead of knowing exactly what hardware your app is running on, Heroku's Dyno Types page gives you... whatever this is:
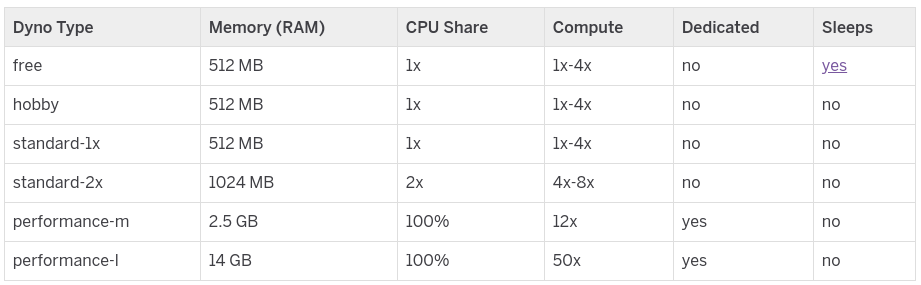
I don't recall Intel and AMD advertising "CPU shares" the last time I bought a computer. What are they? We're not the first to ask this question! Christopher Dignam did some great sleuthing to map the standard dynos to the r3.2xlarge EC2 instance size, and the performance dynos to the c3 EC2 family (at least as of 2019).
Given that an r3.2xlarge has 63 GB of RAM and a standard-1x dyno is limited to 512 MB of RAM, we can infer that such a dyno is sharing its instance with up to 124 dynos. As the r3.2xlarge only has 8 CPUs, this means a worst case performance of each dyno only getting one fifteenth of a CPU core if all the other dynos are active at the same time. If they're not, they can burst up to approximately one quarter of a CPU core. This is not great, especially given that the r3 family already uses slightly worse Intel Xeon E5-2670 v2 CPUs than the Intel Xeon E5-2680 v2 CPUs in the c3 family.
In our experience, Heroku's standard dynos are suitable only for non-user-facing tasks. Good uses include web servers that respond to automated webhooks, and workers that asynchronously process a queue of tasks. Bad uses include front-line web servers serving HTML content to users.
We observed that by switching our user-facing API endpoints from standard dynos to performance-M dynos, we:
- decreased our median response time latency by 43%
- decreased our 99th percentile latency by 56%
- provided a much more consistent user experience with less variance in latency
Below, you can see a ministat diagram plotting the latencies of the endpoint on different dyno types. We did not measure performance-L dynos, as they differ from the performance-M dyno only in RAM size.
x standard-1x + standard-2x * performance-m
* **
***** +
***** * x x * + + + +
******+*+ +**xx*x*+ ** +++++ x+ xx * + x x++ x * x * x x x x
|___MA____| |_|__________M__A____M____A___|_____________________|
N Min Max Median
x 25 0.464784 1.265659 0.691863
+ 25 0.408262 0.953812 0.605436
* 25 0.360387 0.544565 0.392073
So what does this mean for you? If you care about your user experience, you'll have to invest in