Effective CloudFormation
We highlight the most useful bits of CloudFormation that every devops engineer should know.
May 29, 2020 | aws cloudformation devops | by: Colin Dellow
Table of Contents
Introduction
AWS services are the LEGO blocks of the IT world. Businesses can snap together building blocks like SQS queues, EC2 instances, and S3 buckets to rapidly create a service that delivers value.
You can treat AWS like a freestyle LEGO construction project. Just pull pieces from a big bin and put them together until you’re satisfied with the toy you’ve built:

Or you could be a little more rigorous, and follow the (468-page!) instruction manual to produce this 7,541-piece monster:

This is essentially the difference between the AWS Management Console and AWS CloudFormation.
In Amazon’s own words:
The Console provides an assortment of simplified and automated workflows and wizards that make it easier to test and build with AWS services.
AWS CloudFormation allows you to model your entire infrastructure and application resources with either a text file or programming languages.
The console is great for exploratory prototyping, but bad for reproducible infrastructure. Once you switch to defining your infrastructure in CloudFormation stacks, you’ll never look back. Here are a few best practices to help you on your way.
Best Practices
YAML
You can define your CloudFormation stacks in YAML or JSON. You should use YAML.
For starters, there’s a lot less syntactic cruft. Compare the same stack, first in JSON:
And now in YAML:
If that wasn’t enough, YAML also supports:
- comments with the
#character - multiline strings, which are useful for inlining small Lambda functions or EC2
UserDatasections
cfn-python-lint
Imagine you have a very complex CloudFormation stack that creates dozens of resources. Buried in your stack is this buggy code:
Spot the bug? Probably not, and so you submit your stack. After several minutes of CloudFormation churning away, it reaches the buggy part of the stack:

It then spends several minutes undoing the changes. Frustrating!
If you had instead used Amazon’s excellent cfn-python-lint tool to validate your stack, you would have been warned immediately:

Avoid Name Conflicts with Parameters, Pseudo or Otherwise
Defining your infrastructure in a CloudFormation stack means it’s trivial to make copies of it. Imagine a world where every developer can easily and safely test their code changes, without putting production at risk.
This does require some forethought. After all, you can’t have two S3 buckets named the same thing, so stacks with hardcoded names are likely to be hard to duplicate.
To ensure multiple instances of a stack don’t collide with each other, you have a few options:
- Don’t assign a name! AWS will generate a random name.
- Let the user provide a parameter that is incorporated into every name, e.g:
- Use the CloudFormation pseudo parameters. These are predefined variables that relate to details of the stack itself. Two that are particularly useful are
${AWS::StackName}and${AWS::AccountId}.
Note that CloudFormation parameters can be strongly typed. Both simple types, such as String or Number, and AWS-specific types, such as AWS::EC2::AvailabilityZone::Name, are supported. Choosing appropriate types for your parameters helps developers understand what sort of values they are expected to provide.
Intrinsic Functions
CloudFormation templates aren’t merely static text files. The last example used the Sub intrinsic function to replace a placeholder value with a user-provided value. This programmability is what grants CloudFormation much of its power.
The whole list of intrinsic functions is worth reviewing, although we’ll discuss a few particularly powerful ones in more detail in this article.
Conditions
CloudFormation stacks don’t have to be one size fits all. For example, production workloads may require powerful, and therefore expensive, resources. A developer kicking the tires likely won’t require the same amount of hardware. CloudFormation provides ways to conditionally create different kinds of resources.
Conditional Resources
The simplest example uses a condition intrinsic function to declare a Condition that controls whether a resource is created or not.
Imagine a stack that creates a CloudFront distribution. For developer environments, it’s OK to use the auto-generated ddcfg6dsj43sm.cloudfront.net domain name. For production environments, you’d like to do a bit more work and assign a user-friendly DNS entry like example.com.
Line 6 declares the IsProd condition, which tests whether the Env parameter is set to a certain value using the Equals intrinsic function. Line 16 makes the creation of the CNAME record happen only when IsProd is true:
Conditional Attribute Values
Sometimes you need to create the resources in both cases, but with different values for its attributes. The stack below creates a small EC2 instance for developers, but a large one for production, using the If intrinsic function:
Conditional Attributes
Finally, sometimes you need to include an attribute in some cases, and exclude it altogether in others. For this, there is the special AWS::NoValue reference. Think of it like null in a programming language – it can take the place of a primitive value like a string (as in line 6), or of a composite record-type value (as in line 13).
Do This, Then That
Before creating your resources, CloudFormation firsts analyzes them to make a directed, acyclic graph of dependencies. This is how CloudFormation decides which resources to create first, and which can be created in parallel.
For example, a stack that defines a new VPC with a security group, subnet, database instance, and EC2 instance will have this graph:
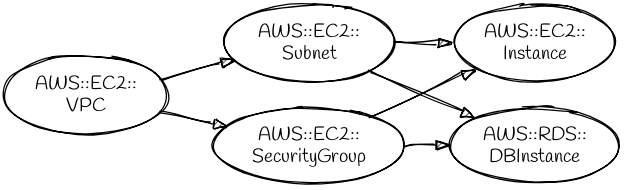
There are some scenarios where you’ll want to fine tune CloudFormation’s default dependency analysis.
DependsOn
The DependsOn attribute tells CloudFormation to wait until the depended-on resource has been created before creating the depending-on resource. Imagine that we wanted the database instance to be fully created before launching the EC2 instance. We could achieve that with this stack:
That would cause the new graph of dependencies to look like this:
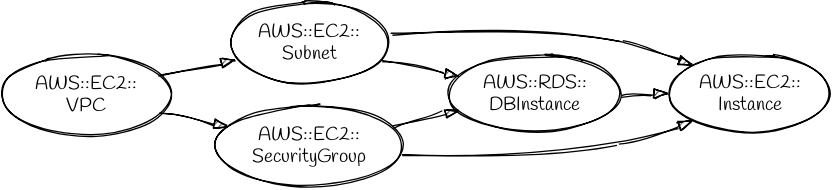
CreationPolicy
By default, an EC2 instance is considered created when it is launched. This is fast, but not always useful. For example, what if you need to install some software and start some services?
The CreationPolicy attribute provides a solution. It prevents an EC2 instance from being automatically marked as created. Instead, to mark it as created, and thus permit the stack to continue creating dependent resources, you need to signal CloudFormation. The easiest way to do this is with the cfn-signal script. A common approach is to provide a UserData script that does your initialization steps and then finishes by calling the cfn-signal script.
Wait Conditions
The CreationPolicy attribute only applies to EC2 instance and auto-scaling groups. Sometimes you’ll need to block progress of a CloudFormation stack pending some external action. In those cases, you can create an AWS::CloudFormation::WaitCondition resource. The WaitCondition can also be signalled with cfn-signal, and other resources can use DependsOn to wait until it has been signalled.
Referencing Values from Stacks
Once you’ve created your stack, you often need to translate from a logical resource ID like S3Bucket, which identifies the resource in your stack, to a physical resource ID like stack-s3bucket-13qb2k9okcsc1, which identifies the actual AWS entity.
There are a few ways of doing this, depending on the context.
Use JMESPath
One option is to use the aws command-line tool to interrogate your stack after it has been created. The aws tool supports the JMESPath query language, which lets you extract the particular values of interest to you:
$ aws cloudformation describe-stack-resources \
--stack-name your-stack \
--logical-resource-id S3Bucket \
--query StackResources[0].PhysicalResourceId \
--output text
stack-s3bucket-13qb2k9okcsc1
You could then pass this value to another stack as a parameter value.
ImportValue
An alternative approach uses the special ImportValue intrinsic function. ImportValue retrieves a previously exported Output value from an earlier stack for use in a subsequent stack.
Imagine that we create a stack which creates an S3 bucket:
In a second stack, we’d like to create an EC2 instance that knows which S3 bucket it should use. We can configure a bash script that runs on instance start up and writes the bucket name to a file for future access:
Note that the exported name of an output value must be unique across all of your account’s stacks in a given region.
Conclusion
CloudFormation is a powerful, flexible tool. While there are many other features we haven’t touched on – macros and YAML anchors and aliases, for example – we’ve highlighted the most useful bits in the list of best practices above. Whether you’re starting out or an experienced user, hopefully you have found something useful.