S3 Throughput: Scans vs Indexes
This article does a deep dive on the mechanics of how the Common Crawl organizes its archives, but it will also be of general interest to folks who work with S3 and EC2.
February 14, 2020 | aws common crawl | by: Colin Dellow
The efficiency of an application often boils down to the efficiency of its data structures. For example, Amazon's S3 service is very popular for "data lakes". A data lake is a large collection of data stored in many S3 objects, where each S3 object typically contains thousands to millions of records. Querying these records efficiently can be the difference between a fast, inexpensive service and a slow, costly one. In this article, we'll dig in to how the Common Crawl structures its data, and how the best way to query it depends on your usage.
The core of the Common Crawl is its WARC archives. Each WARC file consists of approximately 50,000 web page captures stored as 50,000 individual gzip files concatenated together. Per the gzip specification, a sequence of gzip files concatenated together is itself a valid gzip file. This means that if you know where to look inside the larger WARC file, you could fetch just the data you need. To support this use case, the Common Crawl publishes indexes that can be used to locate every individual URL capture:
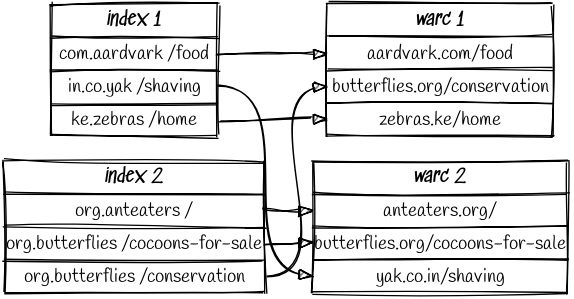
While each WARC is a random sample of the Internet, the indexes are ordered alphabetically by domain name. This leaves consumers with a choice. When processing the Common Crawl, should they scan entire WARC files sequentially, or use the indexes to submit HTTP Range requests to pick and choose only those captures that they're interested in?
The Test Harness
To find out, we wrote two test harnesses. The "batch" harness reads a bunch of WARC files in their entirety sequentially, while the "indexed" harness makes many requests for small ranges of the WARC files. The "indexed" case makes many requests concurrently in order to prevent the latency of each individual request from hurting overall throughput. As usual, we've published our code on GitHub. This is a synthetic benchmark: the only work it does is to uncompress and parse the entry. A real workload might be dominated by other processing, which makes the differences shown here less important.
All tests were done on a 16-core a1.4xlarge instance running Ubuntu 18.04 in the us-east-1 region. Tests using fewer than 16 cores were artificially constrained using the taskset tool. We observed the mean rate of entries processed per second after 60 seconds. If you'd like to reproduce our results, you must use the us-east-1 region -- because it is in the same region as the Common Crawl's S3 bucket, it is the fastest region to use, and incurs no data transfer charges [1].
The Results
We performed 5 trials for each harness, with different numbers of CPU cores. Plotting the rate at which entries were processed, we immediately see two things:
- both batch and indexed access scale linearly with number of cores (a.k.a. our benchmark isn't buggy!)
- batch access has higher overall throughput
We expect the indexed case to be slower. This is because a WARC file contains 50,000 entries, so the indexed case requires making 50,000 times more HTTP requests than the batch case in order to read the same number of entries. The fact that it's only 20-30% slower is a remarkable testament to the high performance of S3!
We do see that the indexed case has a lot more variability. This variability could perhaps be reduced with more tuning effort -- making tens of thousands of HTTP requests per second puts unusual pressures on operating system resources and programming language runtimes.
Next, since S3 offers both HTTP and HTTPS endpoints, we performed the same benchmark, but using the SSL-protected endpoint. This was actually surprising!
The graph shows that the privacy and integrity guarantees of SSL come with a cost. Ideally, we'd see every dot at 100% of the throughput of the non-SSL endpoint. Instead, we see that batch traffic is slowed by 25% and indexed traffic by 35-40%. There's an outlier for the single-core indexed case, which again illustrates the challenge of tuning.
Conclusion
If you need to read every WARC entry, scan them sequentially. Otherwise, strongly consider using the Common Crawl's CDX or Parquet indexes to focus only on the records that are important to you. In all cases, consider using HTTP for best efficiency. More generally, when considering data retrieval patterns, always take the time to measure to see whether an index is faster than a complete scan!
PS: Want to learn more about the Common Crawl? You may be interested in Code 402 Crawls, our platform to make the crawl accessible for marketers, researchers, and programmers.
Notes
- When dealing with data the size of the Common Crawl, transfer charges are no joke! Processing the entire set of WARCs from a single month in a region other than us-east-1 would incur $500-$1,000 in charges, depending on the specific region used.